
Zhicheng Zhang
I am a Ph.D. student in the School of Computer Science at Carnegie Mellon University, where I am fortunate to be advised by Prof. Fei Fang. Before that, I studied computer science in the ACM Honors Class at Shanghai Jiao Tong University, where I was fortunate to be advised by Prof. Weinan Zhang and Prof. Yong Yu.
I am interested in (multi-agent) reinforcement learning, efficient exploration, and the intersection of RL and LLMs, especially in settings where limited feedback makes useful behavior hard to discover. I have also spent time at Meta Superintelligence Labs and ByteDance Seed Post-training, working on LLM post-training and reinforcement learning for language agents. Here is my latest CV.
Email: zhichen3 cs cmu edu.
Selected Publications
* means equal contribution.
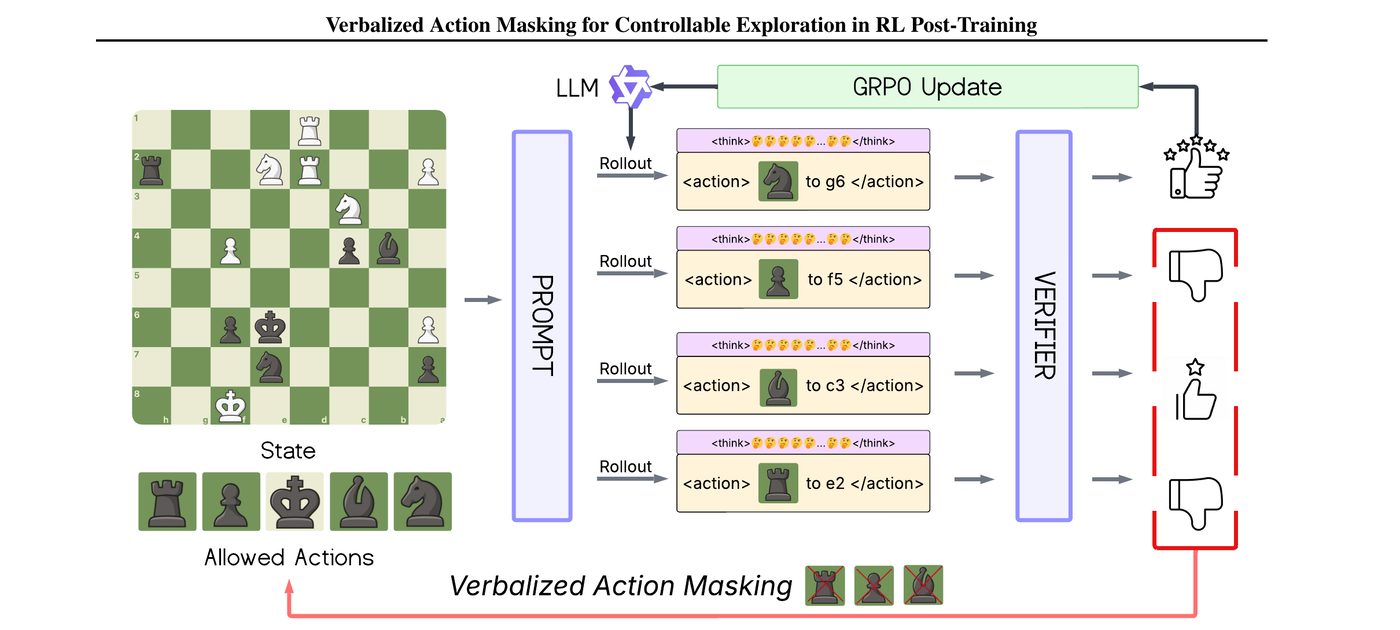
VAM: Verbalized Action Masking for Controllable Exploration in RL Post-Training -- A Chess Case Study.
arXiv:2602.16833; Under Review.
Exploration remains a key bottleneck for reinforcement learning (RL) post-training of large language models (LLMs), where sparse feedback and large action spaces can lead to premature collapse into repetitive behaviors. We propose Verbalized Action Masking (VAM), which verbalizes an action mask in the prompt and enforces that the model outputs an action from the masked set. Building on this interface, we introduce iterative action-space pruning: if the target action is not sampled, we remove valid sampled actions from the mask and resample under the reduced candidate set, repeating until the target is sampled or a fixed budget is exhausted. We study VAM in chess and evaluate it under two training regimes: an engine-play regime that generates states via play against an engine opponent and a fixed-dataset regime that trains from a fixed dataset of positions with verifier scores. Across held-out chess puzzles and full-game play measured by average centipawn loss (ACPL), VAM improves learning efficiency and final performance over strong baselines, highlighting verbalized masking as a practical mechanism for controllable exploration in LLM RL post-training.
@misc{zhang2026vamverbalizedactionmasking,
title={VAM: Verbalized Action Masking for Controllable Exploration in RL Post-Training -- A Chess Case Study},
author={Zhicheng Zhang and Ziyan Wang and Yali Du and Fei Fang},
year={2026},
eprint={2602.16833},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2602.16833}
}
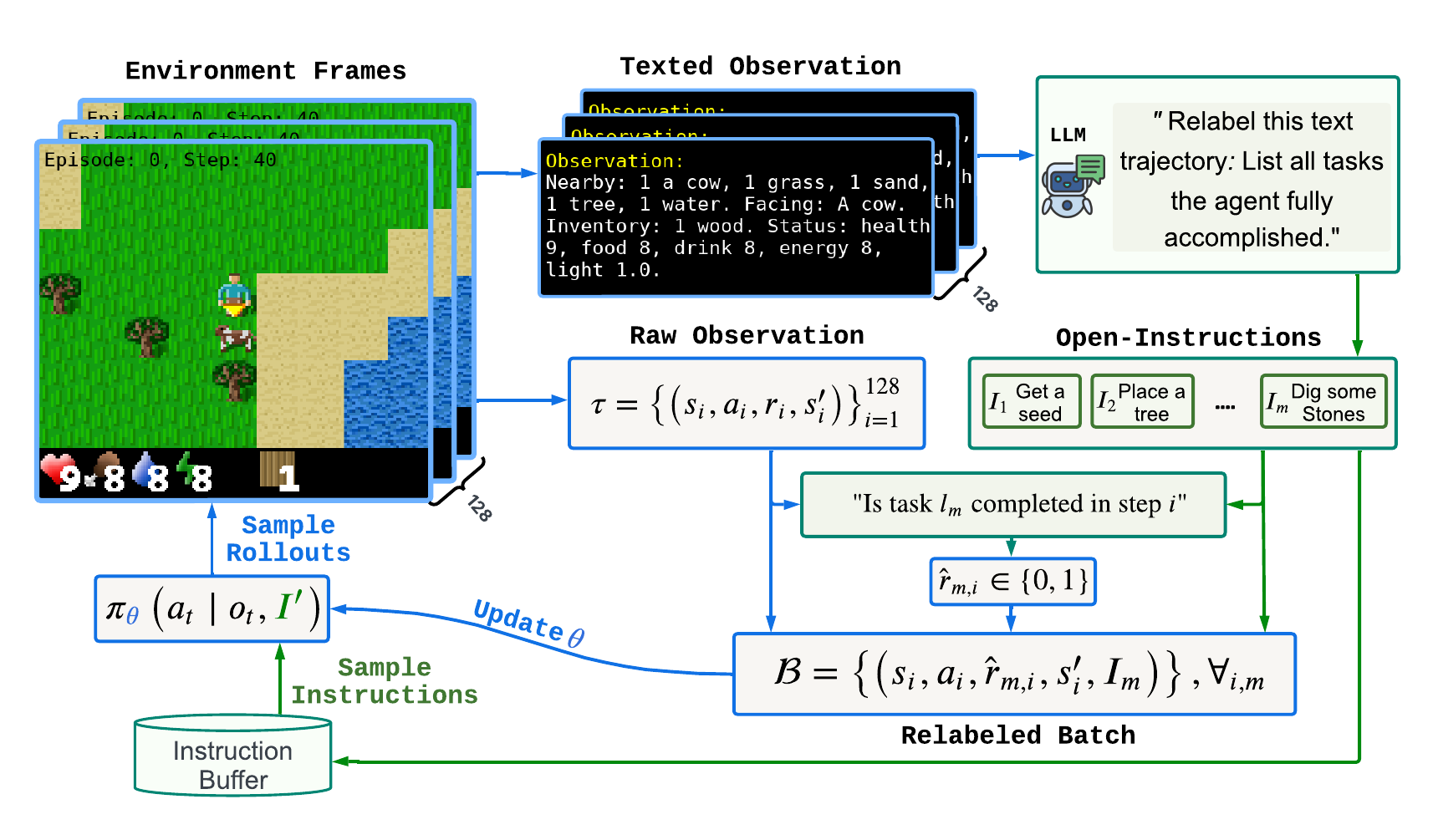
Learning Instruction-Following Policies through Open-Ended Instruction Relabeling with Large Language Models.
arXiv:2506.20061; Under Review.
Developing effective instruction-following policies in reinforcement learning remains challenging due to the reliance on extensive human-labeled instruction datasets and the difficulty of learning from sparse rewards. In this paper, we propose a novel approach that leverages the capabilities of large language models (LLMs) to automatically generate open-ended instructions retrospectively from previously collected agent trajectories. Our core idea is to employ LLMs to relabel unsuccessful trajectories by identifying meaningful subtasks the agent has implicitly accomplished, thereby enriching the agent's training data and substantially alleviating reliance on human annotations. Through this open-ended instruction relabeling, we efficiently learn a unified instruction-following policy capable of handling diverse tasks within a single policy. We empirically evaluate our proposed method in the challenging Craftax environment, demonstrating clear improvements in sample efficiency, instruction coverage, and overall policy performance compared to state-of-the-art baselines. Our results highlight the effectiveness of utilizing LLM-guided open-ended instruction relabeling to enhance instruction-following reinforcement learning.
@misc{zhang2025learninginstructionfollowingpoliciesopenended,
title={Learning Instruction-Following Policies through Open-Ended Instruction Relabeling with Large Language Models},
author={Zhicheng Zhang and Ziyan Wang and Yali Du and Fei Fang},
year={2025},
eprint={2506.20061},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2506.20061}
}
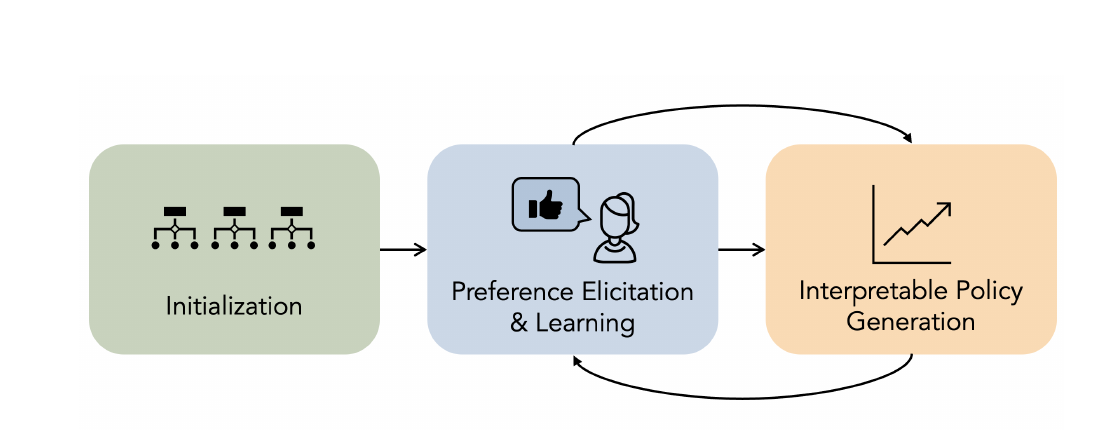
Aligning Agent Policies with Preferences: Human-Centered Interpretable Reinforcement Learning.
The AAAI/ACM Conference on AI, Ethics, and Society (AIES), 2025.
An unaddressed challenge in interpretable reinforcement learning (RL) is to enable AI agents to integrate preference feedback into the policy generation process. Existing methods collect feedback only after training is complete, neglecting opportunities to inform the learning process. To address this gap, we propose a novel framework to align interpretable policies with human feedback during training. Our framework interleaves preference learning with an evolutionary algorithm, using updated preference estimates to guide the generation of better-aligned policies, and using newly-generated policies to query users to refine the preference model. Evolutionary algorithms enable the exploration of the full space of policies; however, it is intractable to maintain separate preference estimates, like win rates or utility values, for each individual policy in this infinite space. To handle this challenge, we propose to represent policies as feature vectors consisting of a finite set of meaningful attributes. For example, among a set of policies with similar performance, some may be more intuitive or more amenable to human intervention. To maximize the value of each user query, we employ a novel filtering technique to avoid presenting policies that are dominated in all dimensions, as repeated selections of clearly superior policies provides little information. We validate our method with experiments on synthetic preference data on two RL environments. We show that it produces RL policies that are not only better-aligned with user preferences but also more efficient in the number of user queries.
@article{milani2025aligning,
author={Milani, Stephanie and Zhang, Zhicheng and Topin, Nicholay and Xia, Lirong and Fang, Fei},
title={Aligning Agent Policies with Preferences: Human-Centered Interpretable Reinforcement Learning},
journal={Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society},
volume={8},
number={2},
pages={1711--1723},
year={2025},
month={oct},
doi={10.1609/aies.v8i2.36668},
url={https://doi.org/10.1609/aies.v8i2.36668},
publisher={Association for the Advancement of Artificial Intelligence (AAAI)}
}
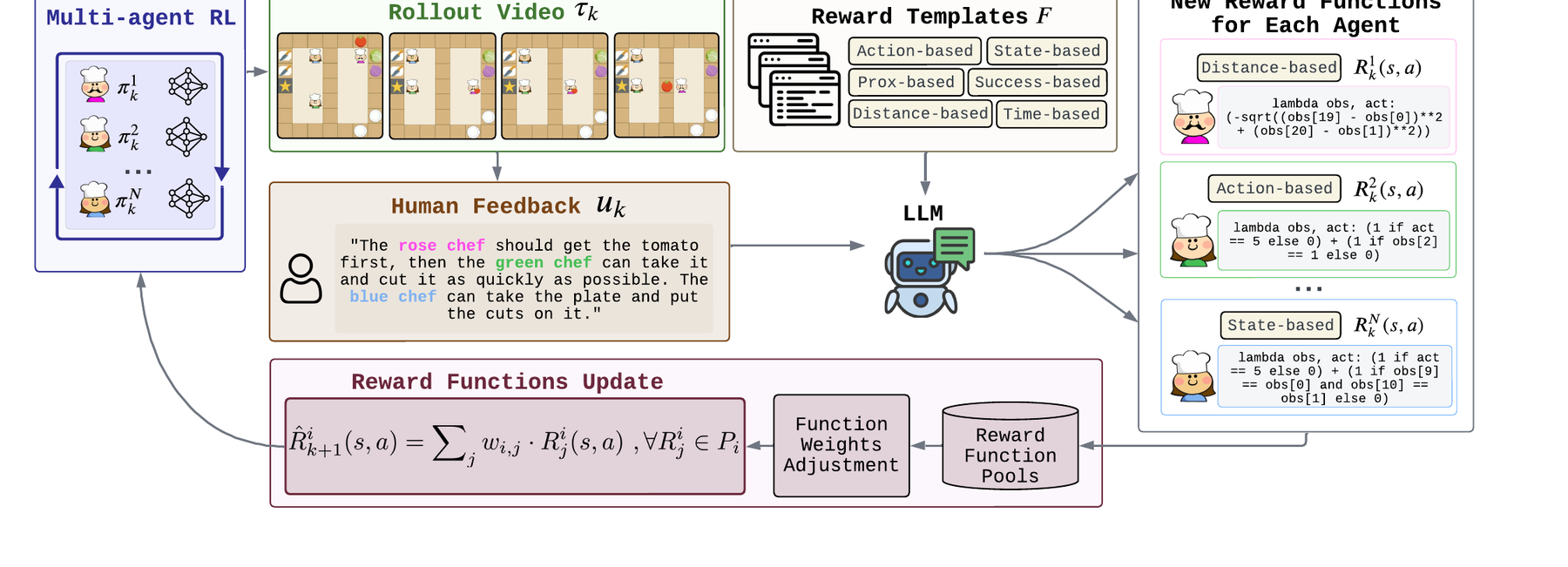
M3HF: Multi-agent Reinforcement Learning from Multi-phase Human Feedback of Mixed Quality.
The Forty-Second International Conference on Machine Learning (ICML), 2025.
Designing effective reward functions in multi-agent reinforcement learning (MARL) is a significant challenge, often leading to suboptimal or misaligned behaviors in complex, coordinated environments. We introduce Multi-agent Reinforcement Learning from Multi-phase Human Feedback of Mixed Quality (M3HF), a novel framework that integrates multi-phase human feedback of mixed quality into the MARL training process. By involving humans with diverse expertise levels to provide iterative guidance, M3HF leverages both expert and non-expert feedback to continuously refine agents' policies. During training, we strategically pause agent learning for human evaluation, parse feedback using large language models to assign it appropriately and update reward functions through predefined templates and adaptive weights by using weight decay and performance-based adjustments. Our approach enables the integration of nuanced human insights across various levels of quality, enhancing the interpretability and robustness of multi-agent cooperation. Empirical results in challenging environments demonstrate that M3HF significantly outperforms state-of-the-art methods, effectively addressing the complexities of reward design in MARL and enabling broader human participation in the training process. Code is available at https://github.com/cooperativex/M3HF.
@inproceedings{wang2025m3hf,
title={M3HF: Multi-agent Reinforcement Learning from Multi-phase Human Feedback of Mixed Quality},
author={Wang, Ziyan and Zhang, Zhicheng and Fang, Fei and Du, Yali},
booktitle={Proceedings of the 42nd International Conference on Machine Learning},
pages={65429--65448},
year={2025},
editor={Singh, Aarti and Fazel, Maryam and Hsu, Daniel and Lacoste-Julien, Simon and Berkenkamp, Felix and Maharaj, Tegan and Wagstaff, Kiri and Zhu, Jerry},
volume={267},
series={Proceedings of Machine Learning Research},
publisher={PMLR},
url={https://proceedings.mlr.press/v267/wang25el.html}
}
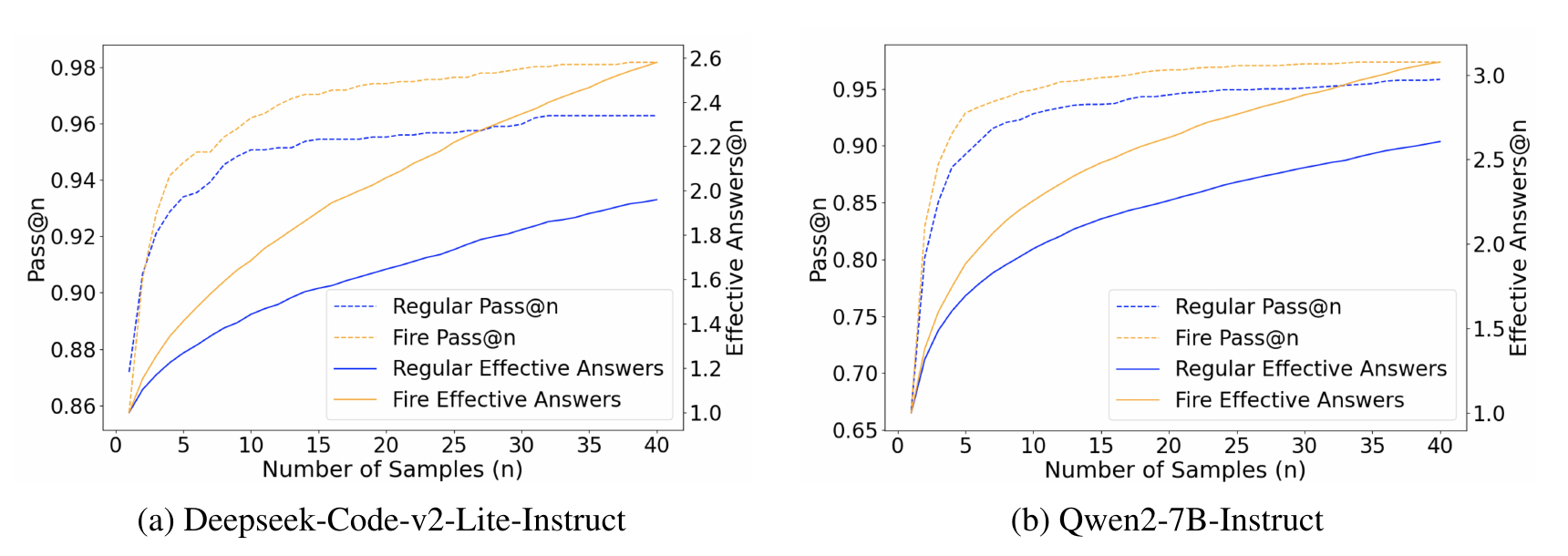
Flaming-hot Initiation with Regular Execution Sampling for Large Language Models.
Findings of the Association for Computational Linguistics: NAACL 2025.
Since the release of ChatGPT, large language models (LLMs) have demonstrated remarkable capabilities across various domains. A key challenge in developing these general capabilities is efficiently sourcing diverse, high-quality data. This becomes especially critical in reasoning-related tasks with sandbox checkers, such as math or code, where the goal is to generate correct solutions to specific problems with higher probability. In this work, we introduce Flaming-hot Initiation with Regular Execution (FIRE) sampling, a simple yet highly effective method to efficiently find good responses. Our empirical findings show that FIRE sampling enhances inference-time generation quality and also benefits training in the alignment stage. Furthermore, we explore how FIRE sampling improves performance by promoting diversity and analyze the impact of employing FIRE at different positions within a response.
@inproceedings{chen-etal-2025-flaming,
title={Flaming-hot Initiation with Regular Execution Sampling for Large Language Models},
author={Chen, Weizhe and Zhang, Zhicheng and Liu, Guanlin and Zheng, Renjie and Shi, Wenlei and Dun, Chen and Wu, Zheng and Jin, Xing and Yan, Lin},
editor={Chiruzzo, Luis and Ritter, Alan and Wang, Lu},
booktitle={Findings of the Association for Computational Linguistics: NAACL 2025},
pages={7133--7142},
address={Albuquerque, New Mexico},
month={apr},
year={2025},
publisher={Association for Computational Linguistics},
isbn={979-8-89176-195-7},
url={https://aclanthology.org/2025.findings-naacl.396/},
doi={10.18653/v1/2025.findings-naacl.396}
}
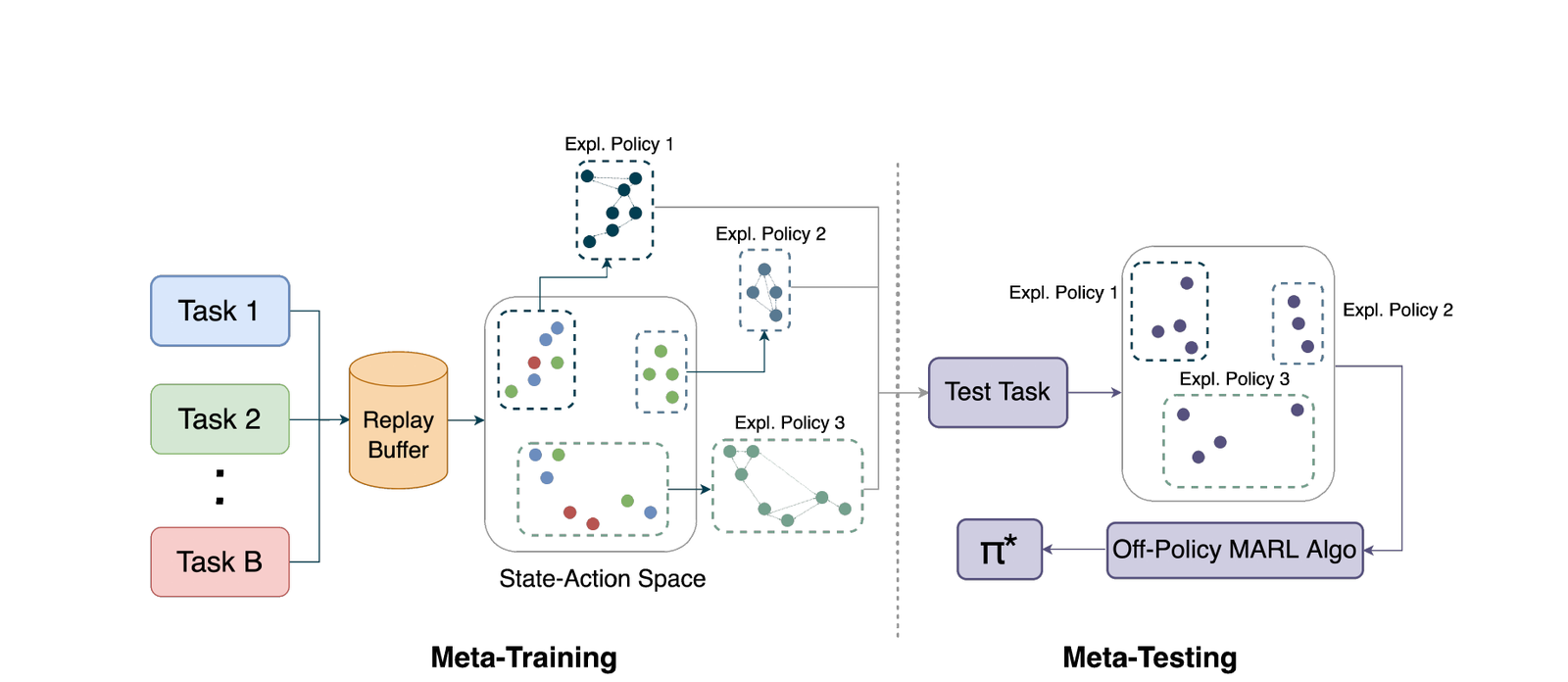
MESA: Cooperative Meta-Exploration in Multi-Agent Learning through Exploiting State-Action Space Structure.
The 23rd International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2024).
Multi-agent reinforcement learning (MARL) algorithms often struggle to find strategies close to Pareto optimal Nash Equilibrium, owing largely to the lack of efficient exploration. The problem is exacerbated in sparse-reward settings, caused by the larger variance exhibited in policy learning. This paper introduces MESA, a novel meta-exploration method for cooperative multi-agent learning. It learns to explore by first identifying the agents' high-rewarding joint state-action subspace from training tasks and then learning a set of diverse exploration policies to "cover" the subspace. These trained exploration policies can be integrated with any off-policy MARL algorithm for test-time tasks. We first showcase MESA's advantage in a multi-step matrix game. Furthermore, experiments show that with learned exploration policies, MESA achieves significantly better performance in sparse-reward tasks in several multi-agent particle environments and multi-agent MuJoCo environments, and exhibits the ability to generalize to more challenging tasks at test time.
@inproceedings{zhang2024mesa,
author={Zhicheng Zhang and Yancheng Liang and Yi Wu and Fei Fang},
title={MESA: Cooperative Meta-Exploration in Multi-Agent Learning through Exploiting State-Action Space Structure},
booktitle={Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2024)},
pages={2085--2093},
year={2024},
publisher={International Foundation for Autonomous Agents and Multiagent Systems},
isbn={978-1-4007-0486-4},
url={https://www.ifaamas.org/Proceedings/aamas2024/pdfs/p2085.pdf}
}
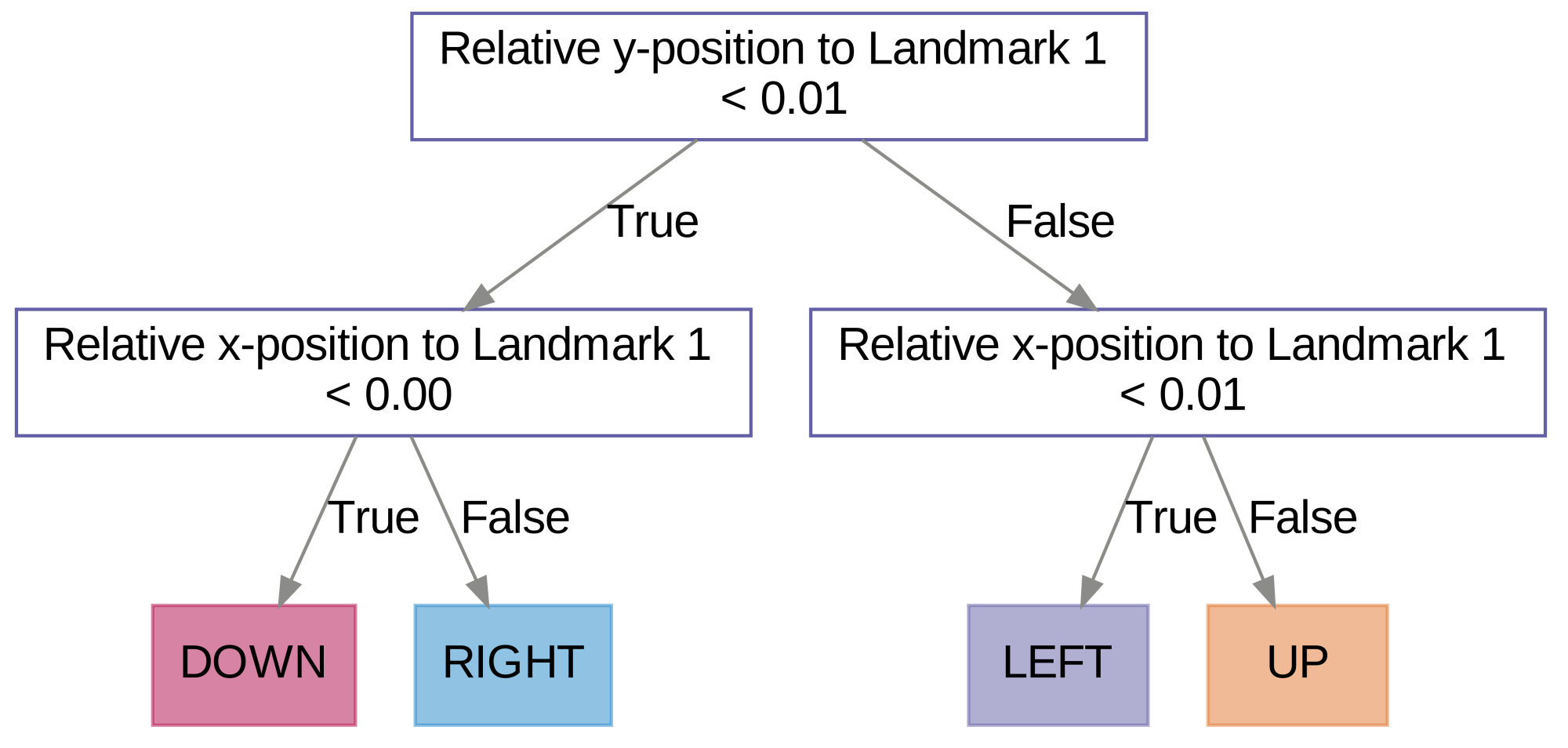
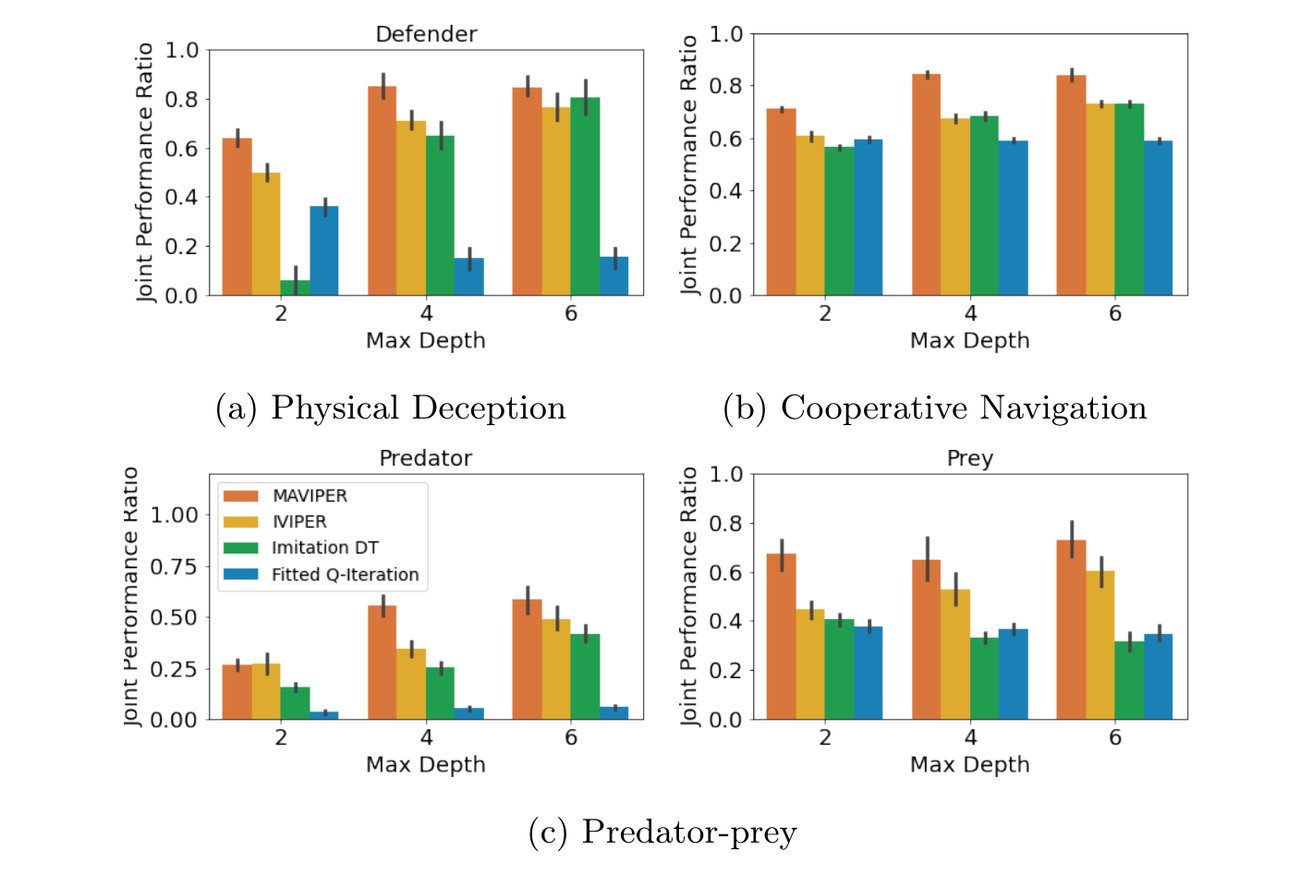
MAVIPER: Learning Decision Tree Policies for Interpretable Multi-Agent Reinforcement Learning.
The European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD), 2022.
Many recent breakthroughs in multi-agent reinforcement learning (MARL) require the use of deep neural networks, which are challenging for human experts to interpret and understand. On the other hand, existing work on interpretable reinforcement learning (RL) has shown promise in extracting more interpretable decision tree-based policies from neural networks, but only in the single-agent setting. To fill this gap, we propose the first set of algorithms that extract interpretable decision-tree policies from neural networks trained with MARL. The first algorithm, IVIPER, extends VIPER, a recent method for single-agent interpretable RL, to the multi-agent setting. We demonstrate that IVIPER learns high-quality decision-tree policies for each agent. To better capture coordination between agents, we propose a novel centralized decision-tree training algorithm, MAVIPER. MAVIPER jointly grows the trees of each agent by predicting the behavior of the other agents using their anticipated trees, and uses resampling to focus on states that are critical for its interactions with other agents. We show that both algorithms generally outperform the baselines and that MAVIPER-trained agents achieve better-coordinated performance than IVIPER-trained agents on three different multi-agent particle-world environments.
@inproceedings{milani2023maviper,
author={Stephanie Milani and Zhicheng Zhang and Nicholay Topin and Zheyuan Ryan Shi and Charles Kamhoua and Evangelos E. Papalexakis and Fei Fang},
title={MAVIPER: Learning Decision Tree Policies for Interpretable Multi-Agent Reinforcement Learning},
booktitle={Machine Learning and Knowledge Discovery in Databases},
series={Lecture Notes in Computer Science},
volume={13716},
pages={251--266},
address={Cham},
publisher={Springer Nature Switzerland},
year={2023},
doi={10.1007/978-3-031-26412-2_16},
url={https://doi.org/10.1007/978-3-031-26412-2_16}
}
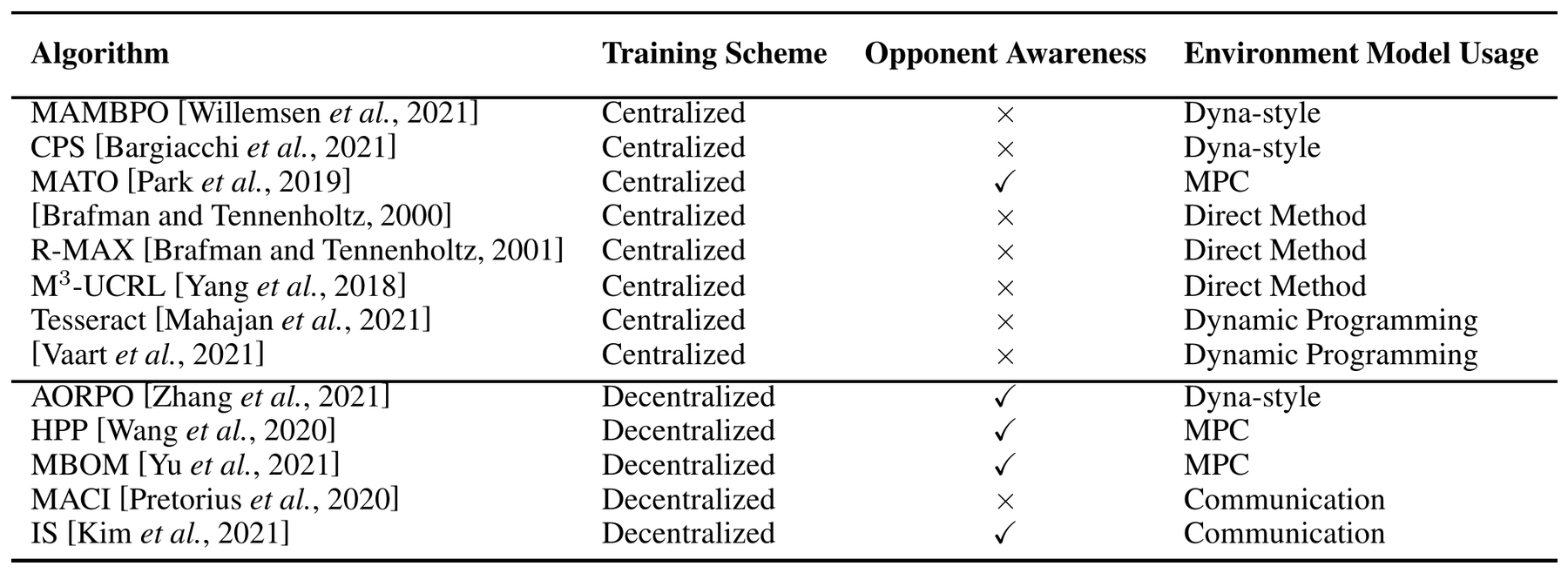
Model-based Multi-agent Reinforcement Learning: Recent Progress and Prospects.
arXiv preprint arXiv:2203.10603, 2022.
Significant advances have recently been achieved in Multi-Agent Reinforcement Learning (MARL) which tackles sequential decision-making problems involving multiple participants. However, MARL requires a tremendous number of samples for effective training. On the other hand, model-based methods have been shown to achieve provable advantages of sample efficiency. However, the attempts of model-based methods to MARL have just started very recently. This paper presents a review of the existing research on model-based MARL, including theoretical analyses, algorithms, and applications, and analyzes the advantages and potential of model-based MARL. Specifically, we provide a detailed taxonomy of the algorithms and point out the pros and cons for each algorithm according to the challenges inherent to multi-agent scenarios. We also outline promising directions for future development of this field.
@misc{wang2022modelbasedmultiagentreinforcementlearning,
title={Model-based Multi-agent Reinforcement Learning: Recent Progress and Prospects},
author={Xihuai Wang and Zhicheng Zhang and Weinan Zhang},
year={2022},
eprint={2203.10603},
archivePrefix={arXiv},
primaryClass={cs.MA},
url={https://arxiv.org/abs/2203.10603}
}
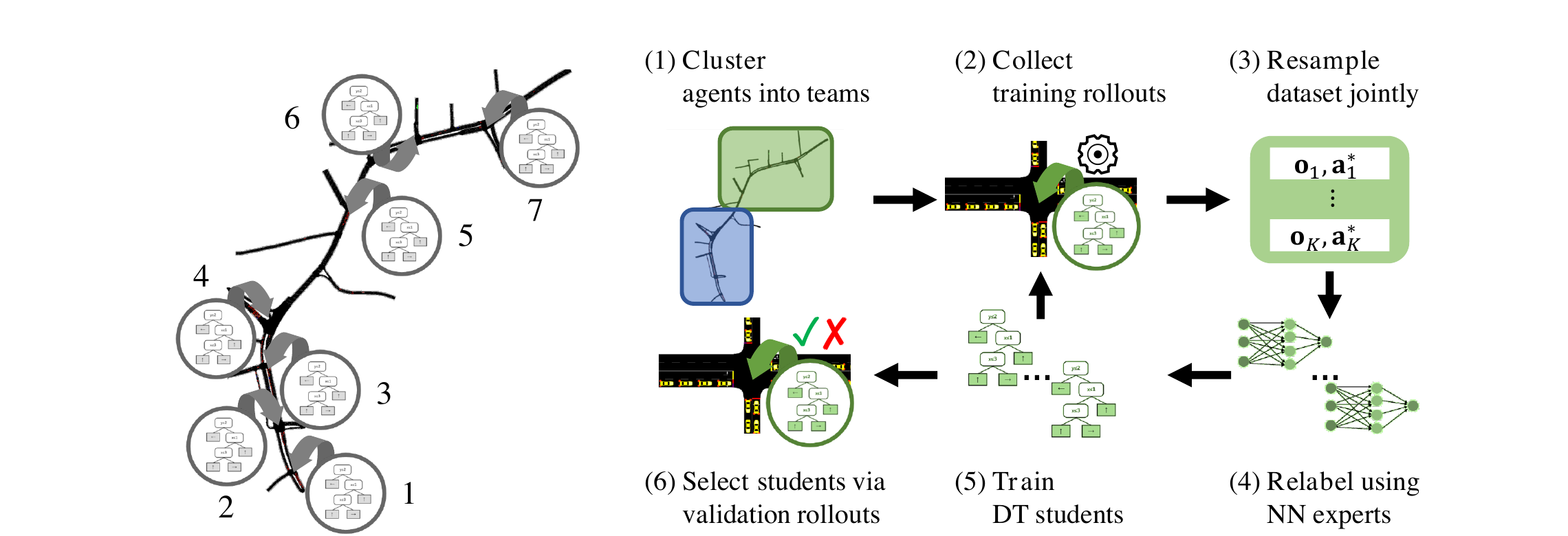
Making Teams and Influencing Agents: Efficiently Coordinating Decision Trees for Interpretable Multi-Agent Reinforcement Learning.
The AAAI/ACM Conference on AI, Ethics, and Society (AIES), 2025.
Poor interpretability hinders the practical applicability of multi-agent reinforcement learning (MARL) policies. Deploying interpretable surrogates of uninterpretable policies enhances the safety and verifiability of MARL for real-world applications. However, if these surrogates are to interact directly with the environment within human supervisory frameworks, they must be both performant and computationally efficient. Prior work on interpretable MARL has either sacrificed performance for computational efficiency or computational efficiency for performance. To address this issue, we propose HYDRAVIPER, a decision tree-based interpretable MARL algorithm. HYDRAVIPER coordinates training between agents based on expected team performance, and adaptively allocates budgets for environment interaction to improve computational efficiency. Experiments on standard benchmark environments for multi-agent coordination and traffic signal control show that HYDRAVIPER matches the performance of state-of-the-art methods using a fraction of the runtime, and that it maintains a Pareto frontier of performance for different interaction budgets.
@article{chen2025making,
author={Chen, Rex and Milani, Stephanie and Zhang, Zhicheng and Sadeh, Norman and Fang, Fei},
title={Making Teams and Influencing Agents: Efficiently Coordinating Decision Trees for Interpretable Multi-Agent Reinforcement Learning},
journal={Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society},
volume={8},
number={1},
pages={567--578},
year={2025},
doi={10.1609/aies.v8i1.36571},
url={https://doi.org/10.1609/aies.v8i1.36571}
}
Interpretable Multi-Agent Reinforcement Learning with Decision-Tree Policies.
In Explainable Agency in Artificial Intelligence, CRC Press, 2024.
Multi-agent reinforcement learning is a promising technique for solving challenging real-world problems involving potentially many interacting entities, such as air traffic control, cyber defense, and autonomous driving. However, policies trained using deep multi-agent reinforcement learning algorithms have thousands to millions of parameters and are challenging for a person to interpret and verify. Real-world risks necessitate learning interpretable policies that people can inspect and verify before deployment. At the same time, policies should perform well at the specified task and be robust to various adversaries, if applicable. This chapter introduces two algorithms, IVIPER and MAVIPER, for learning interpretable decision-tree policies in the multi-agent reinforcement learning setting. It first discusses the critical background for understanding the two algorithms, then presents a detailed explanation of IVIPER and MAVIPER. Next, the chapter includes extensive experiments to validate that MAVIPER produces high-quality decision-tree policies that can more readily coordinate. The chapter concludes by surveying related literature and commenting on avenues for future work.
@incollection{milani2024interpretable,
author={Stephanie Milani and Zhicheng Zhang and Nicholay Topin and Zheyuan Ryan Shi and Charles Kamhoua and Evangelos E. Papalexakis and Fei Fang},
title={Interpretable Multi-Agent Reinforcement Learning with Decision-Tree Policies},
booktitle={Explainable Agency in Artificial Intelligence: Research and Practice},
editor={Silvia Tulli and David W. Aha},
pages={86--120},
year={2024},
publisher={CRC Press},
doi={10.1201/9781003355281-5},
url={https://www.taylorfrancis.com/books/9781003355281/chapters/10.1201/9781003355281-5}
}

Predicting and Presenting Task Difficulty for Crowdsourcing Food Rescue Platforms.
The ACM Web Conference 2024 (Web4Good Track).
Food waste and food insecurity are two problems that co-exist worldwide. A major force to combat food waste and insecurity, food rescue platforms (FRP) match food donations to low-resource communities. Since they rely on external volunteers to deliver the food, communicating rescue task difficulty to volunteers is very important for volunteer engagement and retention. We develop a hybrid model with tabular and natural language data to predict the difficulty of a given rescue trip, which significantly outperforms baselines in identifying easy and hard rescues. Furthermore, using storyboards, we conducted interviews with different stakeholders to understand their perspectives on how to integrate such predictions into volunteers' workflow. Motivated by our findings, we developed three explanation methods to generate interpretable insights for volunteers to better understand the predictions. The results from this study are in the process of being adopted at Food Rescue Hero, a large FRP serving over 25 cities across the United States.
@inproceedings{shi2024predicting,
author={Shi, Zheyuan Ryan and Zhi, Jiayin and Zeng, Siqi and Zhang, Zhicheng and Kapoor, Ameesh and Hudson, Sean and Shen, Hong and Fang, Fei},
title={Predicting and Presenting Task Difficulty for Crowdsourcing Food Rescue Platforms},
booktitle={Proceedings of the ACM Web Conference 2024},
series={WWW '24},
pages={4686--4696},
publisher={ACM},
year={2024},
month={may},
doi={10.1145/3589334.3648155},
url={https://doi.org/10.1145/3589334.3648155}
}
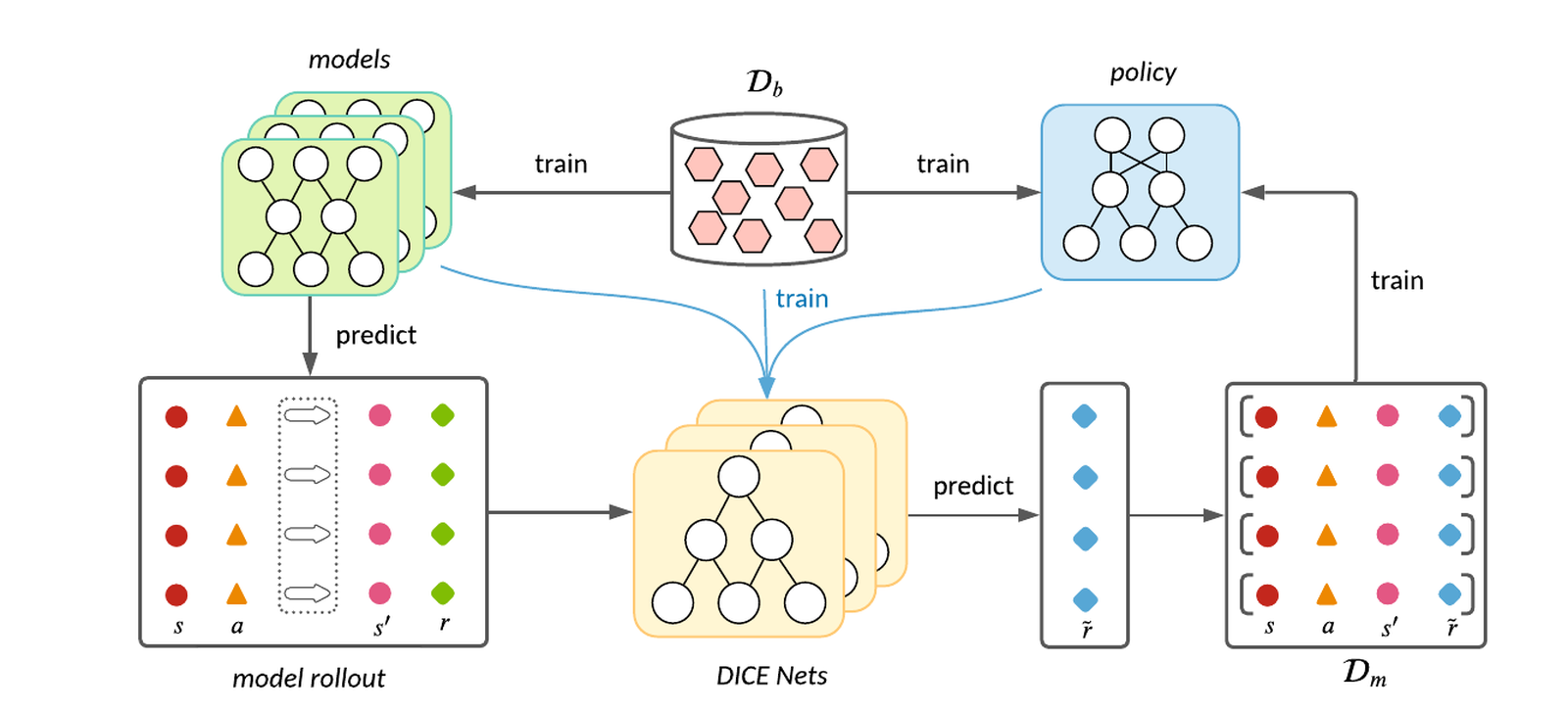
Model-based Offline Policy Optimization with Distribution Correcting Regularization.
The European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD), 2021.
Offline Reinforcement Learning (RL) aims at learning effective policies by leveraging previously collected datasets without further exploration in environments. Model-based algorithms, which first learn a dynamics model using the offline dataset and then conservatively learn a policy under the model, have demonstrated great potential in offline RL. Previous model-based algorithms typically penalize the rewards with the uncertainty of the dynamics model, which, however, is not necessarily consistent with the model error. Inspired by the lower bound on the return in the real dynamics, in this paper we present a model-based alternative called DROP for offline RL. In particular, DROP estimates the density ratio between model-rollouts distribution and offline data distribution via the DICE framework [45], and then regularizes the model-predicted rewards with the ratio for pessimistic policy learning. Extensive experiments show our DROP can achieve comparable or better performance compared to baselines on widely studied offline RL benchmarks.
@inproceedings{shen2021modelbased,
author={Jian Shen and Mingcheng Chen and Zhicheng Zhang and Zhengyu Yang and Weinan Zhang and Yong Yu},
title={Model-Based Offline Policy Optimization with Distribution Correcting Regularization},
editor={Nuria Oliver and Fernando P{\\'e}rez-Cruz and Stefan Kramer and Jesse Read and Jose A. Lozano},
booktitle={Machine Learning and Knowledge Discovery in Databases. Research Track},
series={Lecture Notes in Computer Science},
volume={12975},
pages={174--189},
year={2021},
publisher={Springer International Publishing},
address={Cham},
isbn={978-3-030-86486-6},
doi={10.1007/978-3-030-86486-6_11},
url={https://doi.org/10.1007/978-3-030-86486-6_11}
}
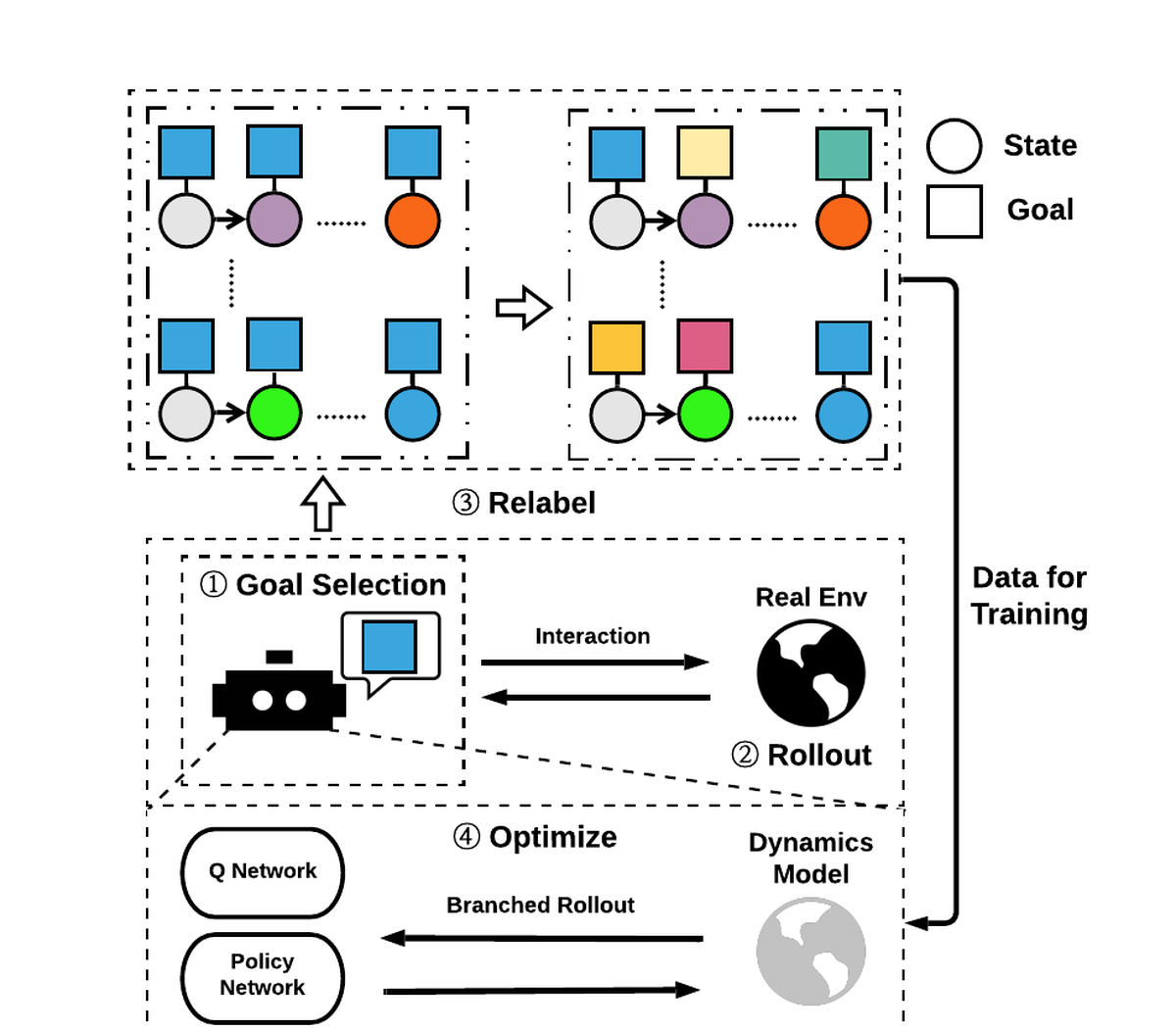
MapGo: Model-Assisted Policy Optimization for Goal-Oriented Tasks.
The 30th International Joint Conference on Artificial Intelligence (IJCAI 2021).
In Goal-oriented Reinforcement learning, relabeling the raw goals in past experience to provide agents with hindsight ability is a major solution to the reward sparsity problem. In this paper, to enhance the diversity of relabeled goals, we develop FGI (Foresight Goal Inference), a new relabeling strategy that relabels the goals by looking into the future with a learned dynamics model. Besides, to improve sample efficiency, we propose to use the dynamics model to generate simulated trajectories for policy training. By integrating these two improvements, we introduce the MapGo framework (Model-Assisted Policy Optimization for Goal-oriented tasks). In our experiments, we first show the effectiveness of the FGI strategy compared with the hindsight one, and then show that the MapGo framework achieves higher sample efficiency when compared to model-free baselines on a set of complicated tasks.
@inproceedings{ijcai2021p480,
author={Zhu, Menghui and Liu, Minghuan and Shen, Jian and Zhang, Zhicheng and Chen, Sheng and Zhang, Weinan and Ye, Deheng and Yu, Yong and Fu, Qiang and Yang, Wei},
title={MapGo: Model-Assisted Policy Optimization for Goal-Oriented Tasks},
booktitle={Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, {IJCAI-21}},
publisher={International Joint Conferences on Artificial Intelligence Organization},
editor={Zhi-Hua Zhou},
pages={3484--3491},
year={2021},
month={8},
note={Main Track},
doi={10.24963/ijcai.2021/480},
url={https://doi.org/10.24963/ijcai.2021/480}
}
Activities
Talks
RL China Seminar (Session 123)
Presented Learning Instruction-Following Policies through Open-Ended Instruction Relabeling with LLMs. Recording.
CHIP Fellows' Symposium, Boston Children's Hospital
Presented Interpretable Multi-Agent Reinforcement Learning.
Service
CMU REUSE Program Mentor
Mentored an undergraduate student with Prof. Fei Fang on interpretable reinforcement learning research using influence functions.
Predictive Intelligence for Pandemic Prevention (PIPP)
- Moderated the panel on disease and misinformation co-evolution for the PILOT Synthesis Workshop (Sep 2023).
- Co-organized the Modeling Intervention Acceptance for Disease Mitigation Workshop (Apr 2023).
Conference and Journal Reviewing
Teaching
Teaching Assistantships
Carnegie Mellon University
- Demystifying AI: Concepts and Applications (17-709) (Fall 2025)
- AI Methods for Social Good (17-737) (Spring 2024)
Shanghai Jiao Tong University
- Practice of Computer Algorithms (MS125) (Summer 2020)
- Data Structure (CS147) (Spring 2020)